Rich-text editors on the web
Our needs
I knew that by working on ![]() Unfold the need for some kind of rich-text editor would come up sooner or later. For the start (while still not supporting an entire full-text), at least some sort of basic formatting for the abstract section of the paper and paper's title would have to exist - subscript, superscript, maybe some special symbols, maybe latex e.g. Full-text would definitely have to include more things such as lists (numbered and bulleted), tables, more advanced formatting (coloring, bold text, italic text), images, maybe some layout adjustments (centered, two-column etc). Something that is currently completely out of scope is things like block or inline comments.
Unfold the need for some kind of rich-text editor would come up sooner or later. For the start (while still not supporting an entire full-text), at least some sort of basic formatting for the abstract section of the paper and paper's title would have to exist - subscript, superscript, maybe some special symbols, maybe latex e.g. Full-text would definitely have to include more things such as lists (numbered and bulleted), tables, more advanced formatting (coloring, bold text, italic text), images, maybe some layout adjustments (centered, two-column etc). Something that is currently completely out of scope is things like block or inline comments.
Our editor also doesn't have to support real-time updates and collaboration (well, not for a while) - the users would write abstracts, comments or whatever other rich-text content on their own time and it would become available only after some explicit "publishing event". There's no need to mutate data within, we can simply fully overwrite the content on every write and it would sufficiently serve our purpose.
Some of our data/models are versioned, concretely, our articles have versions that include a snapshot of both all fields' data and other less tight couplings (files e.g.). Versioning and granular updates don't play nicely (nobody wants a notification for every letter change or a changelog with thousands of versions).
Our database is SQL database, and while they do support JSON data (objects, arrays e.g.) and even JSON queries, some rule-of-thumb is that they should be avoided (not sure if that's changed in the meantime) - in any case, binary data is not a must, and seems that serialized text formats should be sufficient to cover our needs.
I am also still divided on whether Unfold should allow formatting via Markdown (or similar), and I'm currently more against it:
- What you write and what you get is different (i.e. it's not a WYSIWYG editing): and this may confuse people, especially less tech-savvy people.
- Learning curve: for people unfamiliar with Markdown it means that they would have to learn yet another thing, which might not be ideal. We want people to focus on focusing and creating the actual content, not spending time on meta-things. Also, some things such as tables (in Github Flavored Markdown) are done poorly in my opinion - why spend huge amount of time trying to please the parser instead of creating a table in a few simple, visual clicks.
- Markdown is not sufficient: our needs might very easily go beyond Markdown (if they haven't gone over already), and extending the syntax is definitely out of scope.
- Incosistent parsers: from my experience, there are a few parsers available, but mixing few of them in order to support different formatting languages (say HTML + Markdown) is not ideal. I also had problems getting some of the parsers to work nicely and have spend time digging through their own codebase instead of building something valuable within the product.
- Mixing content and semantics: semantics is within the content itself, and that is quite problematic for any kind of data migrations. It is also very problematic that one part of the content can influence another part of the content - syntax builds nested and sibling context in which next parts of the content live (for example lists, or table cells), and going in that direction pretty much binds you to a certain syntax and features that you can/will be able to support.
- The costs of building/integrating and maintenance: it's someone else's code or we need to build it from scratch, and it just very costly.
Even if storing content in Markdown is not desired in our case, providing support for the editor to write Markdown and translate that to whatever exact underlaying format could still be good (starting lists with "- ", copy/pasting Markdown).
Example of what we're going for visually and functionally (from Github):
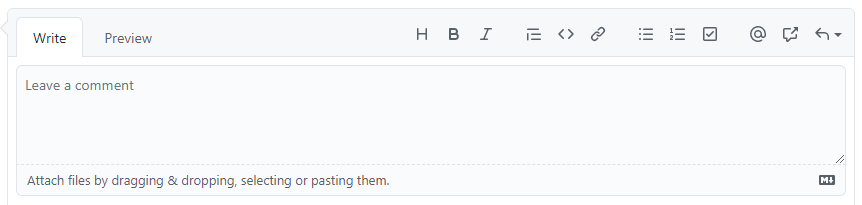
Serialization / deserialization
I will take a look at how a few text editors do their data serialization and deserialization, and what kind of data do they exchange with their servers.
Confluence
Confluence is built around non-real-time editing, so it's much closer to what Unfold needs.
Digging through API exchange with Atlassian (content arrives as part of the response from /cgraphql?q=QueryPreloader_ContentQuery in data.content.nodes.body.dynamic.value), this is the raw data:
When inspecting what kind of data structure this is, you get this:
The content is a nested JSON structure. It arrived as a serialized JSON (serialized and escaped JSON within already serialized JSON API response payload). There's a lot of repetition and ratio of useful content vs total content is much lower than it could be (there's no inferred semantics, but only a very explicit JSON fields), but since this kind of payload that is only exchanged once on publish (mutation / command) and once per read (query), it doesn't even matter that much.
Inline comments can be made without entering Confluence page editor, and action of leaving a new comment sends a "mutation" request.
Notion
Notion was made with real-time collaboration in mind, and it's to be expected that they've made some decisions that would help them achieve that.
Upon digging through network exchange with their servers, you can see this kind of data:
Parsing the meaning of that data yields something like this:
It again has a nested structure (but instead of using objects primarily and arrays for their children, it's just arrays/tuples all the way down), but names and values are shortened and parts of the semantics and syntax and interpreted - "after chunk's value comes its type, and in there we put additional attributes", or "after marking something as comment with "m", the very next thing is the comment's ID", etc. This makes sense because requests can be smaller, saving bandwidth for everyone and computation required to parse and apply data (on the server side and the client side). These choices make sense for real-time collaboration very much.
Comments are made part of a transaction request, and their content shares the same structure as the rest of the content:
Roam Research
Umm, yeah... This kind of stuff scares me. Mixing semantics, content, styling... special syntax, (to me at least) unreadable structure, inferring maybe too much information, and still doing a lot of overwrites instead of inline mutations,...
Haven't spech much time with this data, but it's being exchanged as a part of requests through WebSockets (string on d.b.d./log/-someid.tx in JSON), so if you want to dig in... yeah, good luck.
Google Docs
Their requests and responses are very hard to parse, all changes are sent in small, granular chunks (it always sends minimal information that can mutate existing data, it doesn't seem to add anything extra, i.e. no overwrites, but injections of new mutations). The data when loading the page is sent as part of the page load, so it's either in JS or HTML - either way, making it impossible for us to determine the type of data structure that this is preserved in. CQRS all the way, without even revealing intermediate data structures, which is smart in general, but annoying for us. :)
Comparison & conclusions
Of all the approaches, Confluence's seems closest to our case - no need for real-time collaboration, API exchange can be very verbose and heavy, quite intuitive and easy to work with - no mixing of content, styling and semantics - everything is very explicitly declared.
Data can be easily serialized and stored as a plain text, since there're no inline modifications (due to need to support versioning), this is sufficient and actually a desired approach.
I can see Notion's approach to simply minimizing required syntax as a pretty nice optimization without losing too much flexibility (if any at all).
In conclusion, it seems that Unfold will be picking something along the lines of Confluence. Here's an example of what it might look like:
Thinking about it, we're basically trying to serialize HTML (beacuse that is exactly what we will end up converting all of this into), and it'd be good to separate concerns of semantics and styling (HTML tag) and the content (innerText, innerHTML).
While not talked about it so far, these kind of APIs do allow to be extended with new contnet types. Simply adding a new "type" and handling it on the server and client side is sufficient. Even if things are to be made by users (plugins), you could still point to the right types, for example, with new "custom" type and an attribute that specifies which exact kind it is. So it's pretty future-proof and can be extended easily.
Front-end
- Draft.js
- react-quill